







服务热线
18601611608

2019年8月14日下午,上海风声企业信用征信有限公司主办的《创新 · 拥抱 · 智能》夏季风险管理沙龙活动在上海大酒店成功举办。
上海风声企业信用征信有限公司首席数据科学家廖辰瀚发表了主题为《泛舆情分析与企业知识图谱》的精彩演讲。
廖辰瀚博士毕业于英国Cranfield University, Cambridge-Cranfield High Performance Computing Facility (HPCF) ,上海斯睿德信息技术有限公司首席数据科学家。
曾先后任职于欧洲原子能中心(CERN),英国诺丁汉大学Division of Epidemiology & Public Health,东华大学智能决策实验室、新浪乐居、中国电信等科研院校和企业。
曾任职中国电信云公司和视讯基地首席数据架构师。在机器学习、大数据、人工智能等领域有十多年的科研和产品研发经历,拥有丰富的理论和实践以及产品落地经验。
以下内容根据廖辰瀚博士主题为《泛舆情分析与企业知识图谱》的演讲录音整理:
大家好,我是上海斯睿德信息技术有限公司的技术负责人廖辰瀚。今天跟大家分享我们在泛舆情分析和企业知识图谱领域的一些进展和研究。
首先,什么是知识图谱?用一句话简单来说,用图的形式来组织知识,就是知识图谱。谷歌于2012年首先提出的knowledge graph(知识图谱)概念,然后他把知识图谱这个概念应用到搜索当中,实现了从搜索到答案的一步获得。
在企业风险管理领域,我们认为企业知识图谱同样具有深远意义,主要有两个原因。
第一个原因:企业知识图谱被认为是实现对数据的整合与抽象的最佳方案。以企业为核心的数据维度有几百种,包括工商、司法、舆情、公告等。这些不同来源的异构数据,它天然需要一种模型或者一种数据的组织形式将它有机整合。只有将这些数据整合到位以后,才能360度地分析和评价一家企业。
第二个原因:利用企业知识图谱,可以尽可能地缩短过去递进式的知识探索路径。以前,如果分析一家企业的行业风险,首先需要去获取这家企业的经营范围,它的主营业务,它做什么产品,提供什么样的服务等信息。然后再根据相应的产品和服务的供应链关系,顺藤摸瓜地进一步去做行业分析。
假设现在有一个能够覆盖行业和产品供应链关系的企业知识图谱,通过查询可以一步获得企业相应的行业风险。
如何构建这样一个企业的知识图谱的应用、典型知识库应用?从数据到知识,大致需要一个五层的架构:知识来源、知识加工、知识图谱、知识映射、知识应用。
数据来源是多种多样的,包括结构化、半结构化和非结构化的数据。杂乱无章的数据需要进一步地加工,来整合出我们所要的知识图谱,再进一步地抽象出我们所需要的具体应用,类似于问答、推理、联想、推荐等。
知识加工层,它在原始数据的基础之上进行初步的整合和预处理。这一层实际上包含大量的机器学习的技术,包括知识表示、知识融合、关系抽取、实体分类、事件抽取、舆情属性分类等。
数据经过初步加工,会进入到知识图谱的存储层。这里的知识图谱层是指通用的知识图谱层。通用知识图谱层一般包括百科、Schema和常识三个不同的存储类型,分别存储的是事实、拓扑结构和常识。处理后的结果,再进一步通过知识应用和知识映射,从而实现对终端用户的输出。
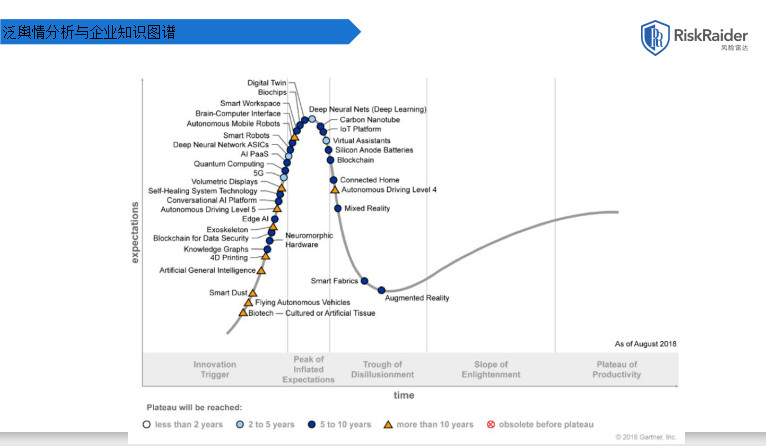
Gartner每年发布的技术趋势曲线,聚焦于未来5到10年有竞争力的新兴技术。从上图中可以看到这几年炒得非常热的深度学习人工智能技术,其主要起点就是深度学习。目前,深度学习已处于高原期,它在未来获得的投资机会与发展会相应放缓。反观知识图谱技术和通用人工智能技术,则分别处于起步阶段和萌芽阶段。从2018年开始,未来的5到10年,我们将迎来知识图谱技术发展和落地的黄金时刻。
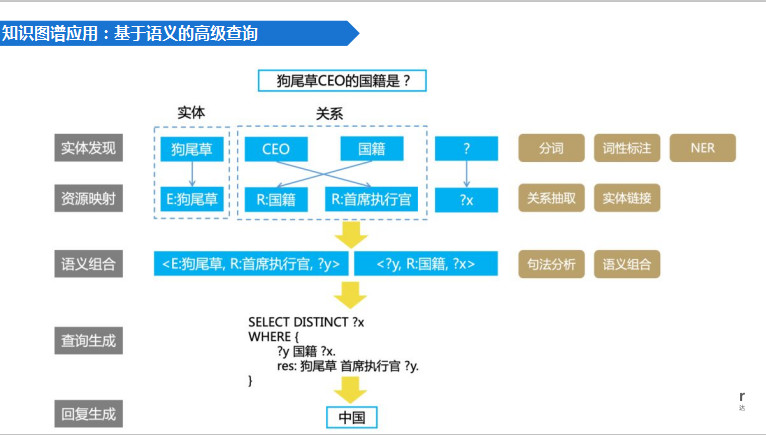
基于语义的高级查询,不同于传统的搜索引擎,要回答上图的问题,我会找CEO的国籍是什么?除非你在搜索引擎里可以找到一模一样的答案!即便找到一模一样答案,它的回答也是五花八门,因为是由网友提供。它并非一个有结构的、经过审核的知识图谱出来的结果。在这种情况下,往往需要一个递进式的搜索方式,要一步一步通过人工的方式获得答案。而通过知识图谱或者领域知识图谱,可以一步触及我们想要的精确答案,大大节约工作效率。
具体怎么做?我们在知识加工层去做实体识别,可以识别出企业,可以识别出植物,可以识别出企业的高管、人名以及国籍等。这些实体和关系,可能来源于不同的文档,存在于不同的媒介。
通过资源映射将这些实体和关系有机地整合和关联,再通过语义组合生成我们想要的查询条件,最后通过计算机执行查询条件,一步获得精确答案。以上三层每一层都有与之相应的技术模块。例如在实际发现上,有分词、词性标注和命名实体识别。在资源映射上,有关系抽取、实体链接……所有的这些技术都是我们目前人工智能的一个分支。
NLP所要研究的内容。它到底难不难?我的答案是难、非常难。NLP研究领域有一句话,自然语言理解是A.I皇冠上的明珠。利用A.I的各种应用去识别图片,去进行人机对话,去过验证码,去理解语言。
为何说自然语言理解是A.I.皇冠上的明珠?语言是人类独有的功能。人类经过了几万年的进化,终于可以用语言来表达思想、意图、情绪,甚至是价值观。人类可以用一个比较中性的陈述来描述昨天吃过的一道菜,也可以用阴阳怪气的口吻去评价之前工作过的一家公司。让计算机去理解人类的这些语言,是不是很难?答案一定是很难。人类若要克服这些难点,需要像蚂蚁啃大象一样一点一点地去做。

上图的这段话,想要让计算机去理解"it",就是指代"london"这个词。实际上这就是一个阅读理解的过程。在初中、高中和大学里我们都做过中文和英文的阅读理解题,其中的一类题型,就是去寻找指代关系,看你有没有把握了全文的主题和主旨。
怎么具体去做非结构化文档的计算机处理逻辑?怎么让计算机理解这些语义?
计算机理解一篇文章的语义,就是一个从下往上的过程,是一个从字词、短语、段落到篇章逐步递进的一个过程。计算机首先要去弄清楚每一个词,每一个字的上下文语义,再经过线性的组合、非线性的映射,最后得到整篇文章的语义。
在每一个具体的级别上,词级别、句级别、篇章级别都有大量的技术模块与之对应。在词和字级别,有分词、NER、词性标注、依存分析与句法分析,在篇章和段落有篇章分析、自动文摘、信息抽取、歧义消解等。
既然字和词是语义理解的基本单位,那么计算机是如何表征这些基本信息单元的?数据表示的是计算机处理和机器学习的基础工作。文本数据首先要转化成机器可理解的形式。
如果两个词字面不同,例如麦克风;与话筒;,人可以定性的去理解它们指的是同一样东西。而实际上它们会有一些细微差别,但这个差别无法量化。在计算机语言里和计算机程序里,如何刻画它们的不同,就需要一种模型去量化它们。
2017年出现的新技术叫词向量模型,又叫word2vec。它的字面意思就是把一个词转换成一个vector、一个向量,并通过大量无监督学习,从大规模的文本中学习出一个词的向量表示方法。
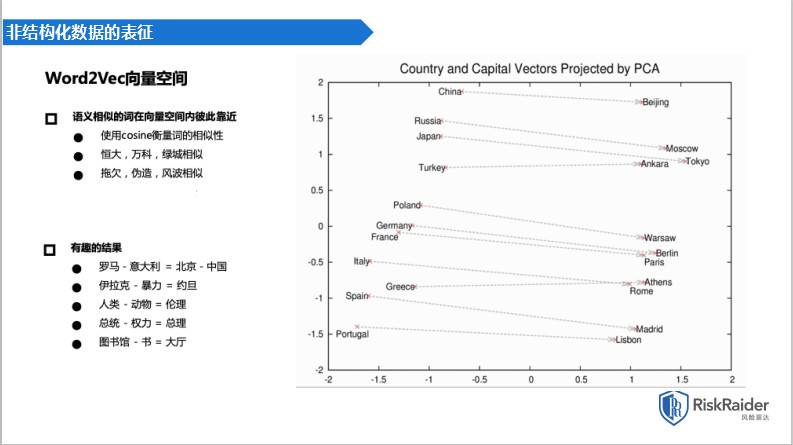
通过大量的非结构化文本,比如说维基百科、百度百科,我们学习了大量的词汇,然后把这些词汇映射到商业空间。
在向量空间表示以后,既然它是向量,我们就可以进行线性代数的加减乘除操作。有些词的概念差别可以被计算机计算出来,例如恒大;、万科;、绿城;比较相似,拖欠;、伪造;、风波;比较相似,因为相似的词同属于一个语义范畴。
但一个有趣的结果就是罗马;与意大利;之于北京;与中国;,它们中间相差的一个概念就是首都。伊拉克;减暴力;等于约旦;,人类;减动物;等于伦理;,总统;减权力;等于总理;,图书馆;减书;等于大厅;,通过向量映射,可以去计算这些语义上的概念差别。从这一步开始NLP世界的大门就打开了。
风险雷达泛舆情维度应用的发展,从1.0演化到3.0,经历了三个阶段。
2016年,风险雷达1.0,这时还只能做一些简单的情感分析,判断全文的正负,针对全文去做一些通用的舆情分类,政治的、军事的、娱乐的等。效果不是很好,原因在于技术问题。2016年的主流技术是利用特征工程加分类算法。影响最终输出的往往是特征工程的好坏。特征工程主要做特征,需要大量的人工干预,在质量和效率上没有办法做到很好的把控,所以它的效果并不理想。
2017年,我们工具箱里增添了两个新工具,一个是word2vec词向量模型,另一个是长短期记忆网络LSTM。不仅将舆情相关的模块做得更精准,而且有了新的后端形态——命名实体识别。
2018年,注意力模型加双向的LSTM横扫整个NLP圈,我们有了更多的场景,除了做命名实体识别之外,还做裁判文书的胜败诉,抽取受诉的事件。不仅多了很多场景,而且将相应的模块更精准化。
2019年,谷歌的最新技术BERT模型出现了,它是一个跨时代的技术。同时,风险雷达更新到了3.0。当我们针对一家企业进行风险扫描,理解它所有的裁判文书,做它所有的舆情分析,我们20秒内就能完成!
风险雷达3.0的舆情分类对比2.0,分类的准确性提高了5.2个百分点。一篇舆情的分析和计算时间只需要零点一秒。
到明年我们可以预见的是:第一,司法舆情全面量化入模;第二,基于知识图谱的检索和分析,我们一步触达;第三,文档的自动摘要。
BERT带来的是一个全新的视野:不再通过人工标注。传统的自然语言的理解研究需要大量的人工干预打标签,而这种质量和效率是不可接受的。
BERT还带来一个全新的学习方式:基于大量文本的半监督学习。它先学习出一个预训练模型,例如:读了大量的维基百科,知道词和词之间的关联关系,知道AK47和mp5的区别。在这个基础之上,只需要针对业务进行模型的微调,在这个模型上再架一个小模型,这个小模型是针对其他的分析,比如说财务分析、舆情判别、风险概率分析等等。很快就可以得到想要的东西,付出的却是相对来说较少的人工干预打标签的过程。
命名实体识别,是构建企业知识图谱的第一步,也是非常重要的一步。围绕企业的数据有很多,需要识别跟企业相关的人,企业名、地址、人员关系、产品、行业等,这些数据从何而来?很少的一部分来自工商,很大的一部分是来自于非结构化数据,包括司法数据。非结构化数据也可以叫泛舆情分析。
例如有一篇《孙宏斌旗下乐视股份全部被质押》的文章,把它交给模型,输入是这篇文章的每一个字,输出是每一个字属于一个特定实体的概率。而后选取概率高的结果作为输出,比如说,第一个字孙;属于人的概率有多大,宏;属于人的概率有多大,最后阅读完这篇文章,就会提取该篇文章涉及的企业、人、地址、人员关系和商标品牌,最终把它落地存储到我们的知识图谱中。风险雷达3.0,已经可以探测出一百多种的命名实体,仅舆情部分就有近50种。在收购重组类的舆情下面,就有收购企业、被收购企业、收购金额,股权金额。通过阅读一篇上市公告,将其中一段话定性为收购重组,就可以提取出这些要素,进而存储到我们知识图谱中,并打上时间戳。当然一系列的这些分类上面都会有这些命名实体被识别出来。
事件提取,也是构建企业知识图谱的重要一环。司法文书是企业风险管理中一个非常重要的数据来源。
司法文书非常冗长,不管是官方的裁判文书网,或者其他的司法裁判文书网在做一些相对而言结构化数据筛选时,包括案由的分析筛选、当事人的筛选,筛选出的文书缺乏事实部分的内容。所以,上诉人、原告、被告、被上诉人的事实部分的数据浓缩和精炼能力是不够的。
风险雷达3.0要做的就是克服这个问题,根据库里8000万文书的事实部分进行浓缩和精炼,提取出要素,存储在知识图谱里。比如说我们有这样一段话,一审原告龙城支行诉称,1999年某月某日,某公司经水泥机械公司提供担保,在该社借款xxxx元,经过我们的程序,我们会自动提取四个要素,借款人、发生时间、担保人和借款金额,这四个要素就会存储进我们的知识图谱,在下一次进行评级,或者事件分析,我们的模型会进一步的关注到这个事件。他曾经发生过这样一个担保事件。
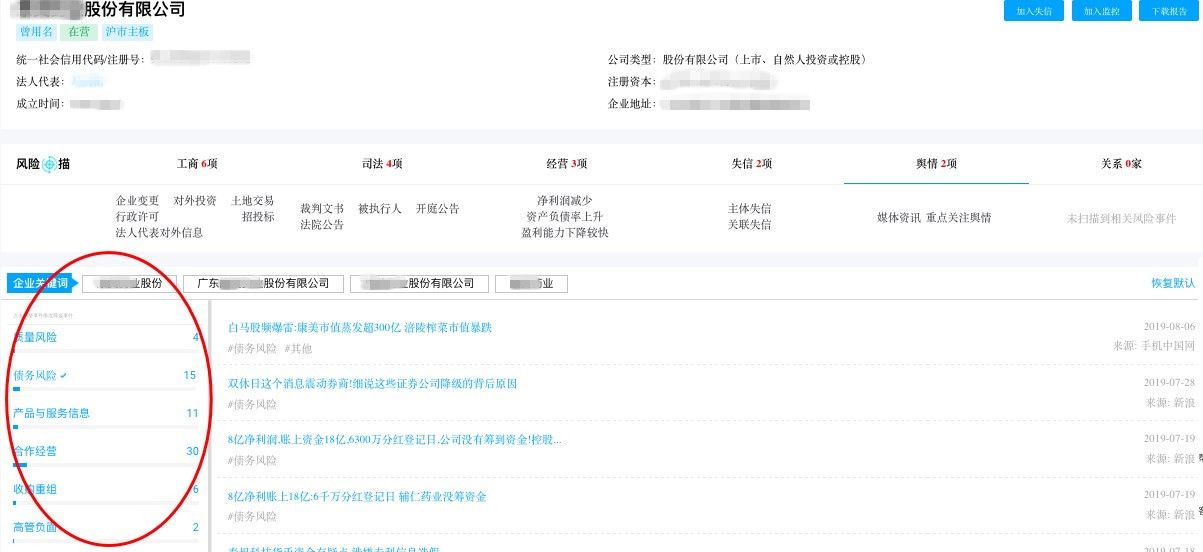
NLP系统风险雷达3.0,在风险扫描的页面输入一家企业的名称之后,系统会马上去搜集这家企业对应的所有维度的数据,实时地获取,并进行整合与加工,及入库分析,在线更新知识图谱,最后给他评价打分,做完这些只需要20秒不到。
在评价打分之前需要先把数据抽象到一定程度。舆情分类就是我们抽象标签的一个重要步骤。一篇非结构化的舆情,如何把它抽象到相应的分类中?
传统做法是用舆情的系统去做。大供应商的系统有一个共同的特性,就是基于全文的分析。如果一篇上市公告包含一百家上市公司,而每家上市公司都有一段话,此时给出的结果是针对这篇全文的。没有具体针对哪一家公司的上下文去做判断,这很致命。
全国有1亿多家公司,在推送的这篇舆情中,怎么样去识别关注的这家企业,就需要用到命名实体识别。识别出舆情中的企业,然后跟关注企业进行完全匹配,若发现它确实出现在里面,这个时候它才有可能成为分析目标。
接下来做的是相关性分析:这篇舆情到底和我的关注企业有没有关系?如果说它出现在舆情里就是目标企业,这个逻辑是不对的。例如,今天斯睿德CEO赵杰参加了一个行业峰会,讲了一段话。这篇文章主要讲这个会议,只出现了一次斯睿德,仅一次的出现跟公司的风险没有任何关系,对公司的风险判别没有参考价值,这个时候它就是不相关的。如果我们系统把这种信息不断地推送给客户,客户不会喜欢,这因为这是数据的爆炸。首先需要剔除的就是这部分数据。
在确定了相关性之后,做正负面判别,判断出这篇文章到底是正面还是负面,是否跟风险相关。接下来再做风险归类,判断它是财务风险、质量风险、环保处罚,还是等等其他的类别的风险。也可能它有正面的风险,比如说新品发布、成果奖项等,所有的这些标签都会被识别出来。
我们所使用的判别模型,从标签到数据,并不是数据越多越好。有了许多标签,最终将它抽象成两种模型。一种是分类模型,就是我们最终打标签,是好是坏抑或什么类型的风险。另一种是因果模型,不需要给它一个硬分类,可以用概率分布来刻画事件之间的因果关系。
评级打分,就是分类模型。在做分类模型的时候,评价模型除了考虑所有的标签之外,还会考虑到这些标签发生的时间区间,然后将它进一步地派生出若干个子标签,结合企业的基本面信息,包括行业信息、关联企业的风险传递等,最终给它打分。
硬分类的评价模型是有一个致命缺点的。所有评价系统最终都会上升到一个评分,而这评分有一个共性就是它是一个黑盒模型。
有时客户想要了解评分的逻辑到底是什么,因而需要一个白盒模型。我们风险雷达3.0,提出了一个因果分析模型。
人们往往对事物本身的因果关系存在主观上的认识,在感性上可以识别因果关系,但没有办法定量分析。在识别单一的因素时,比如涉案裁判文书和未来拖欠货款的因果关系,有可能忽略其他的附加因素。多变量的因果关系很难量化分析,传统的线性分析难以捕捉非线性因果关系,同时没有办法通过结果去反推因;的可能分布。
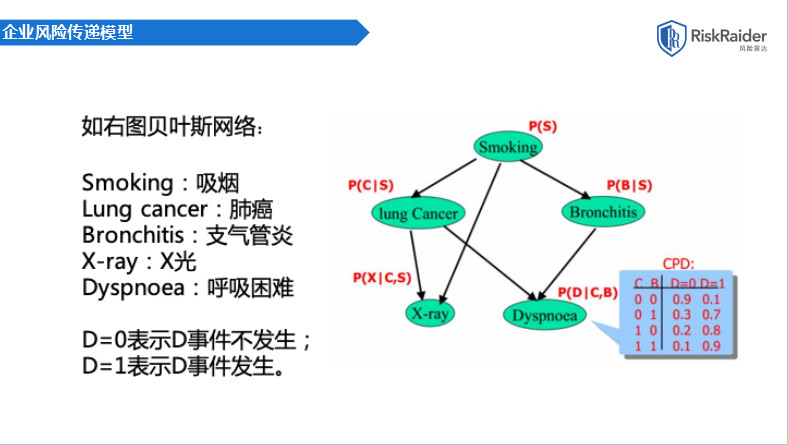
这是一个简单的一个demo。最早我们用的技术是贝叶斯网络。举一个医学领域的例子:抽烟和呼吸困难到底有没有直接关系?肯定回答没有直接关系。但是有没有间接关系,一定有。这个间接关系究竟有多大,能不能计算出你今天抽烟了。一个烟民抽烟抽了十年,未来出现呼吸困难的可能性有多大,怎么计算?这时就需要通过贝叶斯网络,通过间接的概率分布去计算。同样我们可以把我们的企业风险管理领域的一些事件套用在这个模型里,我们可以看到demo金融败诉金额和欠费之间没有直接关系,但它有间接关系,可以计算出来。
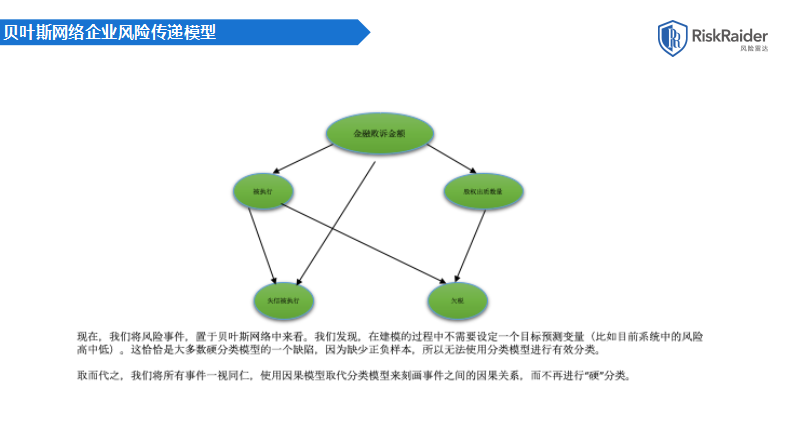
通过初步训练,可以获得三个模型,第一个是根据人为想象建立的一个网络结构。箭头从一个地方指到另外一个地方都存在因果关系。第二个模型,是通过贝叶斯网络跑出来的。根据大量的历史数据观测到的事件跑;出来的一个模型。把第一个模型和第二个模型进行有机整合,就得到了第三个模型,也是我们最终使用的模型。
这个模型怎么用?在任何一个节点进行输入,所有其他的节点都可以成为输出。输入金融败诉的数量作为一个区间,第五个区间的数值,我们就会得到整个网络上其他事件它的概率分布,金融败诉的金额的调整会导致欠税的可能性有多大。
向模型输入不同的金融败诉金额,变量的输出概率在不停的变化。此时我们就摒弃了传统的硬分类模型,没有直接打分,而是给了它整个网络的概率分布。同样,我们输入不同欠税金额,也可以得到其他事件的概率分布。
第一,概率图模型,结合图论模型结构以及模型输出,通过数据可视化展示。它简单直观,是一个白盒模型。可以判断概率,可以知道什么原因导致这个概率变大。
第二,模型基于概率论的因果推断,所有过程是可推导和解释,避免了黑盒操作,结论有据可依。
第三,已知部分企业数据,可以推导其他未知企业的未知信息的概率分布。并非所有的事件每一家企业都可以观测到,一般来说对于风险只能观测到部分事件,可以根据部分事件套用在我们的网络里推出它可能未知的事件的概率分布。
第四,通过模型的训练,从同行业的数据中挖掘所有变量显性及隐性因果关系,我们的模型是根据行业,而每个行业的模型是不一样的。谢谢大家!
